




Business Applications Using Natural Language Processing
With our expertise and experience on Natural Language processing we have developed few applications which has impact on specific customer use case.
We have solved problem using Natural language processing as below:
- Spam filters check.
- Optical Character recognition.
- Grammar check
- Laboratory report check
- Text Clustering – To fetch result.
Here we are trying to explain NLP using text dataset input and result output based on text.
As per the selected data formats, technology companies create clustering algorithms that further generate clusters. These companies have to first create and convert text data into a digital matrix format as per the available data. As a top app development & IT software company, we had to use information retrieval techniques TF–IDF (term frequency-inverse document frequency) in one of our NLP-based solution projects.
The solution had to choose categories of the year which can auto-select the idea among the all. We worked on the answer to create main clusters based on repetitive keywords and types of keywords. Also, we divided the sub-clusters based on the main groups. However, we further analyzed the length of the provided dataset or in which category it is well placed.
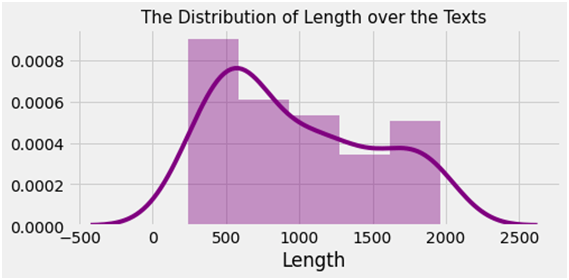
Fig. Distribution of length over the text
TF-IDF is a numerical statistic that precisely reflects how significant a word is to a document in a collection or corpus. The TF-IDF value boosts proportionally to the number of times a word appears in the document and is offset by the number of records right in the corpus that contains the word, which assists in adjusting for the fact that some words appear more often.
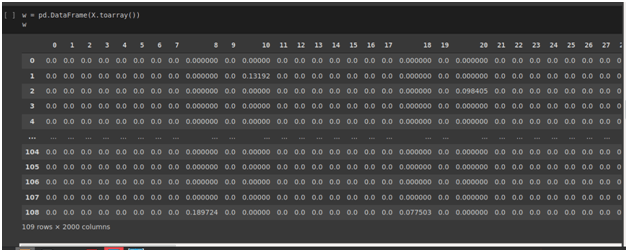
Fig. Digital corpus was created with the help of TF-IDF (term frequency-inverse document frequency).
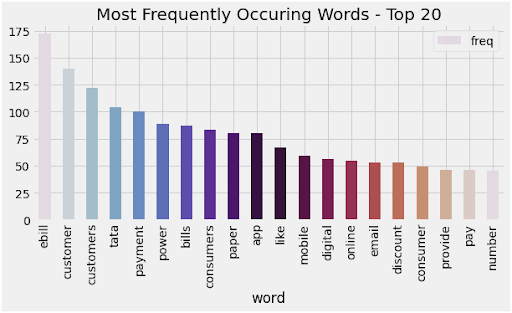
With the data in hand, there were some impurities that we addressed in the project. The impurities included Lower Casing, Removal of Punctuations, Stop-word removal, Common word removal, and other text data preprocessing. Through the bar chart, we also analyzed that some words were repeated and had more occurrences in the dataset.
Use of Clustering Algorithm
With clustering, we grouped a set of objects so that the cluster objects are more similar to each other than those in diverse clusters. We divided the population or data points into several groups, like data points in the same groups, similar to other data points in the same group than those in other groups. The aim was to segregate groups with similar traits and assign them into clusters.
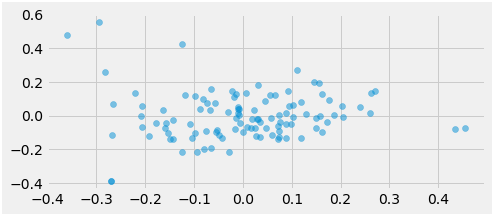
Fig: entries before clustering
We used K-means clustering for the above dataset, a vector quantization method, from signal processing with the objective to partition n observations right into the k clusters. Each observation precisely belongs to the cluster and with the nearest mean serving as a prototype of the cluster.
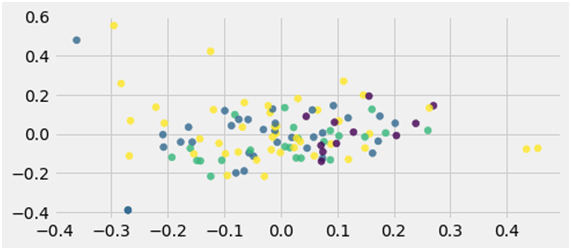
Fig: entries after applying K-means clustering algorithm
Application of Clusters Representation
For displaying clusters, we utilized the D3.js collapsible tree structure in the project. D3.js is a precise JavaScript library used for manipulating documents which are based on data. D3 assists you to bring data to life using HTML, SVG, and CSS. D3 emphasizes web standards and offers you the complete capabilities of modern browsers without tying yourself to a proprietary framework. It blends powerful visualization components, and takes a data-driven approach to DOM manipulation.
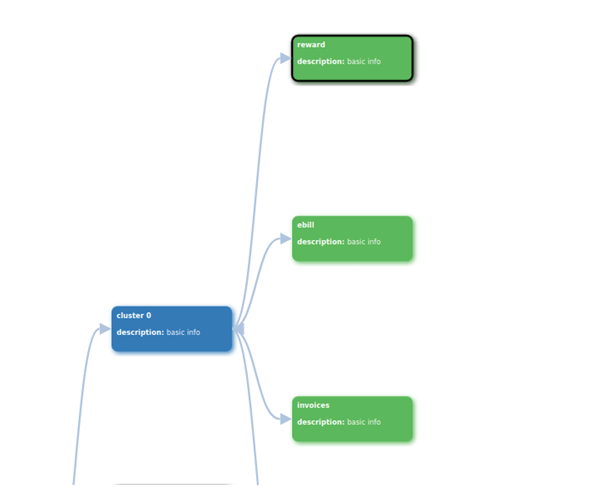
Fig: Tree structure of clusters
By analyzing the above tree structure, we can say that every cluster has certain words that offer more weightage. In cluster 0, we have three words, which are rewards, ebill, and invoices. When we click on one of the words, the next cell is populated with an idea list. This collapsible tree will be extremely helpful for idea management. We can add more detail for idea description in additional cells. The design and structure of the above collapsible tree structure can be transformed as per the requirements.
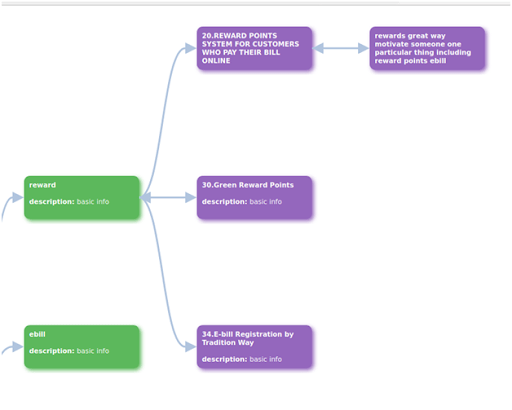
Fig: List of entries fall inside reward which is in Cluster 0
Key Takeaways
In this blog post, you learned about the distribution of length over the text, digital corpus created with TF–IDF, use of Clustering Algorithm, and K-means clustering algorithm. Do you have any questions about NLP Clustering concepts? You can leave a comment, and ask your questions and we will provide you the best answers. You can contact us for more information.












